This site requires cookies to provide you with the best possible experience.
By clicking "Allow," you consent to use them. If you don't,
the site will work with reduced functionality.
Zero to Mastering Software Architecture
Learning Path
For software developers, aspiring architects, product managers/owners,
engineering managers, IT consultants and anyone looking to get a firm
grasp on software architecture, application deployment infrastructure and
distributed systems design starting right from zero.
Zero to Mastering Software Architecture learning path educates you step by step on the
fundamentals of software architecture, cloud infrastructure and
distributed system design, starting right from zero. This unique learning
path offers you a structured learning experience taking you right from
having no knowledge on the domain to making you a pro in designing
web-scale distributed systems like YouTube, Netflix, ESPN and the like.
The Path Consists of Three Courses:
Web Application and Software Architecture 101
Cloud Computing 101 – Master the Fundamentals
Design Modern Web-Scale Distributed Applications Like a Pro
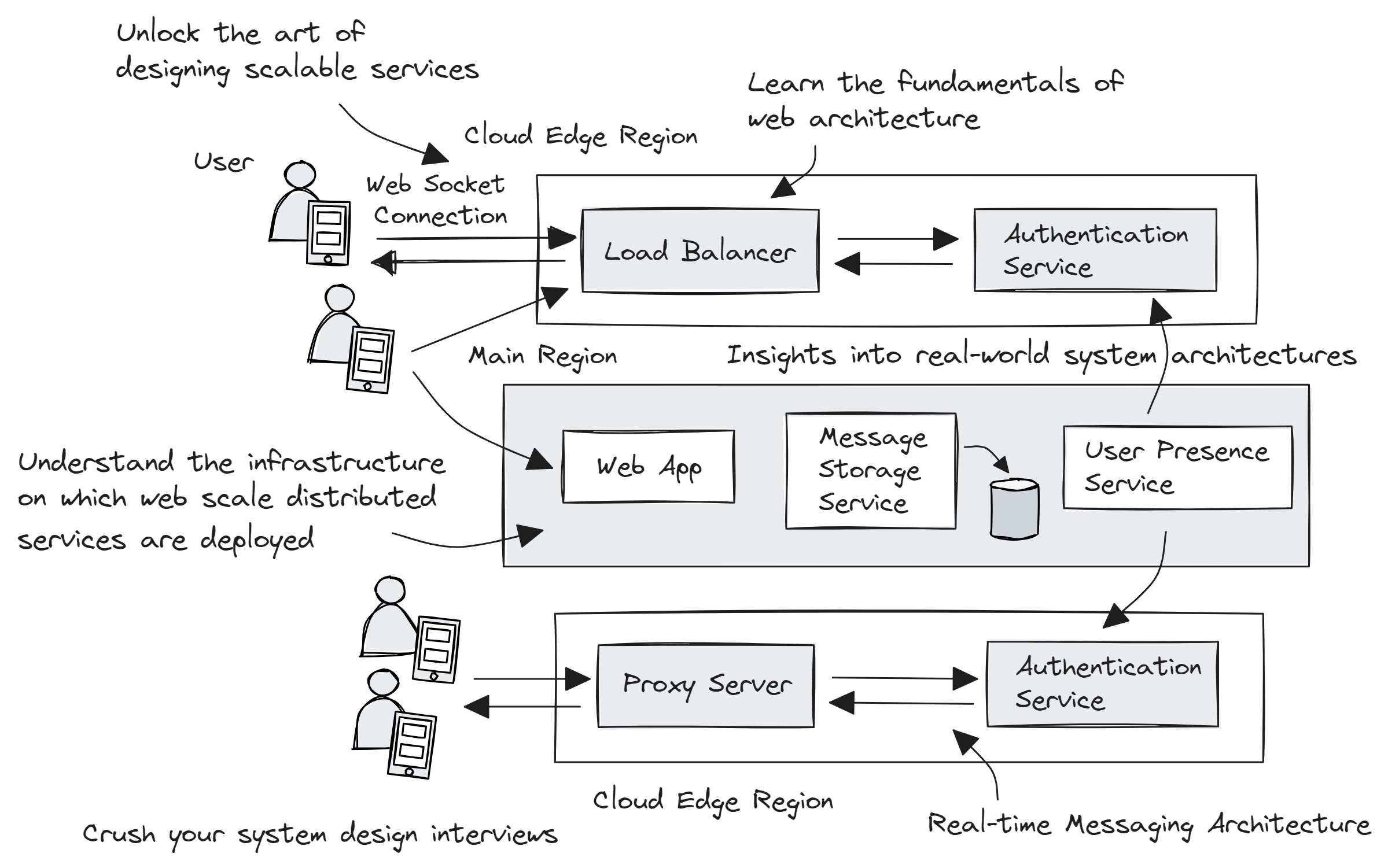
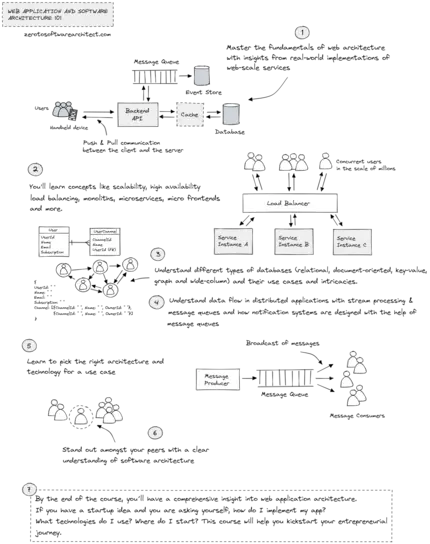
The first course in the learning path, Web Application, and Software Architecture 101, makes you a master of web architecture fundamentals. It walks you
through different components that are involved when designing the
architecture of a web application. You’ll understand the techniques of
picking the right architecture and the technology stack to implement a
use case, including the technology trade-offs involved—further details
on the course page.
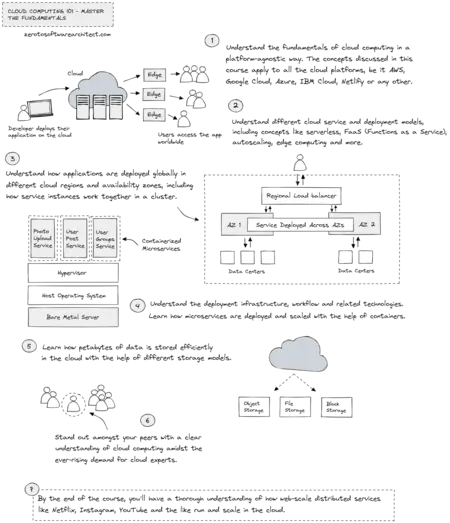
The second course, Cloud Computing 101 – Master the Fundamentals, is a platform-agnostic cloud course that helps you understand the
underlying infrastructure on which distributed applications run.
You’ll gain insight into how services are deployed in different cloud
regions and availability zones globally, how multiple server nodes in
a cluster communicate with each other, how microservices scale in
containers, code deployment workflow and much more—further details on
the course page.
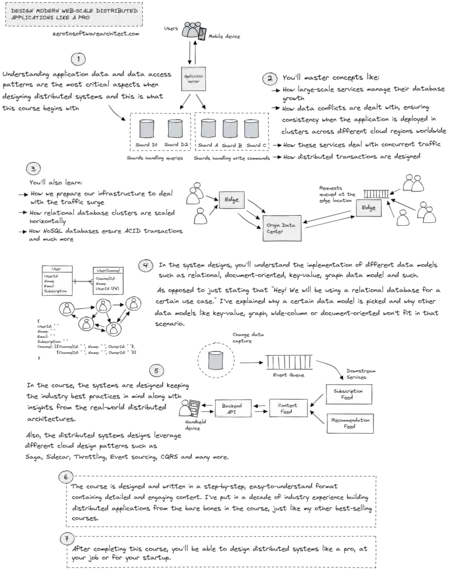
The third, which is also the last course in the learning path, Design Modern Web-Scale Distributed Applications Like a Pro, helps you understand the criticality of understanding application
data and data access patterns when designing distributed systems.
You’ll also learn different data models, the techniques and
intricacies of scaling databases, distributed transactions, handling
concurrent traffic and more.
Applying these concepts and those discussed in the above two courses,
we then design web-scale distributed services like ESPN, Netflix, New
York Times and more—further details on the course page.
You can purchase the courses separately through respective course
pages or the complete learning path at a discounted rate below. The
preview lessons will be available on the respective course pages.
You’ll have 5 years of access to the course content. Please read the
FAQs below before making the purchase.
Who is this Learning Path for?
This learning path is meant for software developers, aspiring
architects, product managers, product owners, engineering managers, IT
consultants and anyone looking to get a firm grasp on software
architecture, application deployment infrastructure and distributed
systems design.
With this learning path, not only you’ll be interview-ready for your
system design interview rounds for any company on the planet, including
FAANG, but you will also develop a solid foundation on the domain,
becoming a better software engineer as a whole.
Will this Learning Path Be Helpful In My Career Growth?
This learning path is the fastest way possible to master distributed
systems design. As opposed to going through tons of articles, videos,
books and whitepapers, you’ll find all the needed concepts in this
learning path which will save you months, if not years, of your time.
I’ve spent a decade developing and managing distributed systems for the
big guns in the industry and I’ve put that experience into the content,
designing the systems with an industry-oriented approach leveraging
different cloud design patterns and such.
Mastering application design gives us an edge as a developer or in any
role that entails decision-making. When implementing new features in our
application, when designing new modules from the bare bones or when
trying to scale our service, we can make better decisions by applying
our architecture knowledge, saving ourselves or our employer a ton of
money. This skill will make you stand out amongst your peers.
Most internet companies today have an essential software design round in
their interviews, regardless of whether you are an absolute beginner or
someone with years of industry experience. They want you to be an
individual contributor. They want you to take ownership of your work and
be capable of designing and writing software from the bare bones all by
yourself, without relying on anyone for assistance.
The Zero to Mastering Software Architecture Learning path prepares you for just that
and more. Investing in this course will significantly increase your
knowledge in the domain, subsequently increasing your pay scale. I wish
I had a similar learning product in the initial years of my career.
Are There Any Prerequisites to this Learning Path?
There are no prerequisites to taking this learning path. However, the
courses should be read in the same order as discussed above. The courses
deal in high-level design providing a thorough discussion on
architectural concepts with the help of several illustrations to help
you understand the concepts better.
Why is this Course Text-based?
My courses are intentionally text-based. The text format of the course
enables you to learn faster than the videos. Learning through reading is
way faster than sitting through hours of videos. It is easy to take
notes—no pausing the videos to take notes or screenshots of diagrams.
You can always go back to specific topics immediately when you need
them.
Also, my courses are frequently updated. New information is continually
added. It is easy for me to update the text-based content as opposed to
re-recording a video every time a tiny update needs to be made. Imagine
that. It would be killing.
How Long Do I Have Access to the Course Content?
You will have up to five years of access to the course content from the date of
purchase.
Why Aren’t You Offering Lifetime Access?
I would be happy to but cannot primarily due to two reasons:
1. I have significant recurring monthly expenses in the form of platform
fees, hosting charges, marketing, international tax compliance and other
maintenance costs. Offering lifetime access would significantly spike
the price of the courses. In order to keep the content affordable, I had
to time restrict access to the platform.
2. The content of my courses is continually updated besides the new
content that is added. The software design and development domain
continues to evolve and as it evolves the courses get updated
accordingly. With my courses, you’ll stay on top of the latest
developments in the domain. And, as you might have figured this demands
continual time investment 🙂
Hello there, I am Shivang. I have industry experience of more than ten
years designing and developing scalable web systems, right from idea to
production. I’ve designed, developed, and maintained code, as well as
worked in the production support for systems receiving millions of hits
every single day.
I’ve worked on large-scale web services for some of the industry giants in
several domains, including E-commerce, Fintech, Telecom and Travel &
Hospitality. My last job was at HP as a full-stack developer in their
Technical Solutions – R&D team.
As an independent consultant, I’ve helped businesses build scalable
services with fitting software design and technology. This included
helping them improve their development processes resulting in better code
quality, maximum test coverage, minimal bottlenecks, less technical debt
and fewer bugs.
Here is my LinkedIn profile if you want to read more about my professional experience or want to say
hello! Cheers!!
Student Reviews
Check out what those enrolled are saying about my courses here.
Check Out My Blog
I write about distributed systems, software architecture, cloud, system
design and backend engineering in general on my blog
scaleyourapp.com Check it out.